About Dan: I'm a computational data journalist and programmer currently living in Chicago. Previously, I was a visiting professor at the Computational Journalism Lab at Stanford University. I advocate the use of programming and computational thinking to expand the scale and depth of storytelling and accountability journalism. Previously, I was a news application developer for the investigative newsroom, ProPublica, where I built ProPublica's first and, even to this day, some of its most popular data projects.
You can follow me on Twitter at @dancow and on Github at dannguyen. My old WordPress blog and homepage are at: http://danwin.com.
How to get started with open-source
In response to a reddit/learnprogramming thread on working on other people’s projects:
The best way to get started in open source software is to add a feature to a project that you actually need. Besides the karma boost from contributing to open-source, you get two very personal benefits:
- By taking the time to integrate your change to the code base, you end up learning a lot about a “real” project is done. Oftentimes I’ll learn smarter ways to organize my code and/or the existence of a helpful library. More often than not, I’ll see that a programmer much better than me wrote some ugly code that just works…and I’ll realize that I need to stop nitpicking my own code to death.
- Even if your contribution is rejected or ignored, you still get to use it to do whatever you needed to do in the first place.
Some examples from my Github history:
I recently contributed a change to the united-states/congress-legislators project, a data project that scrapes and organizes information about every U.S. congressmember. The change I added was a script to contact Twitter’s API to fetch a user’s unique ID from their screen name (as screen names can be changed): https://github.com/unitedstates/congress-legislators/pull/303
I’ve written lots of Twitter-fetching scripts before so the API calls weren’t hard (especially with Tweepy)…however, having to integrate it into their framework of data scrapers forced me to look through some of their implementation details, such as how to arrange the scripts, what interfaces to expose…and I also got to notice some dev environment stuff that I never use, such as Travis CI. And I learned about the rtyaml library, which is one of @unitedstates’s many helpful data projects. I use the Congress data for lots of projects, and I needed to have the Twitter IDs to more accurately analyze social media data…even if they had rejected my pull request I still benefited from writing out the code.
Another example I have is phasion, this Ruby library for doing dupe detection of images. I needed a class to make one of its attributes publicly accessible…the algorithm and its details are far above my head but I do know how to modify a class definition.
The best way to get started is to just start with even the most trivial things, such as fixing typos in documentation; my first Github contributions were minor grammar changes. Then, move up to adding documentation, which can greatly impact people who use the project. And then finally, add new code features. If you’re like me and don’t work on a team and use version control on a day-to-day basis, even doing simple, non-technical pull requests helps you get confident about the open-source process.
Interesting FOIA datasets and ideas from MuckRock
To learn the scope of what American investigators and reporters want to know out about their government, there’s no better place than MuckRock’s Freedom of Information requests list. Filtering the list by Status==Completed will show requests in which a government agency delivered something besides a rejection, but the full list is worth checking out for story and data ideas, as well as just seeing how freedom of information requests are initiated and handled.
A few of the completed requests that caught my eye. These links show the original request; click on the Files tab to see direct links to the responsive documents:
- California 12525 Data (deaths in local and state custody) - Excel files for 2013, 2014, and 2015. In 2014, there were 679 deaths; MuckRock’s blog post here.
- Insane Clown Posse [FBI] - A 121-page scanned, partially-redacted PDF. Read MuckRock’s blog post here.
- 1995-2012 U.S. Recreational Boat Accident Database - a Microsoft Access database.
- 2009 - 2011 FOIA Logs for Office of the Pardon Attorney - partially redacted, OCR’ed PDFs
- FTC Complaints: eHarmony - An XML of 231 partially-redacted complaints about eHarmony from 2010 to December 2013.
- FTC Complaints about OKCupid - An XML of 20 partially-redacted complaints about OKCupid as of October 2013 (are there fewer people unhappy about OKCupid? Or just far more eHarmony users?)
- Adult Homework (Gilbert) - Apparently there was some shitstorm about 4th-graders being assigned homework in which “the student was expected to explain what was happening in a situation where a woman finds another woman’s hair clip under the bed.”
- Arizona Marijuana Citation Data - A scanned PDF of a table of data records from 2011 to October 2014.
- Arlen Specter FBI File - Many scanned and partially redacted PDFs from the FBI File on U.S. Senator Arlen Specter.
- Automatic vehicle location database (Lewis County Sheriff’s Department) - A MySQL database of the past 30 days of AVL data as well as the MySQL schema.
Best and free R-language resources shortlist
Similar to my free Python guides list shortlist, here’s a shortlist (YAML-version) of best and free R books, guides, and tutorials:
Beginner’s guide to R: Introduction – by Sharon Machlis – “Our aim here isn’t R mastery, but giving you a path to start using R for basic data work: Extracting key statistics out of a data set, exploring a data set with basic graphics and reshaping data to make it easier to analyze.”
Beautiful Data chapter: “Bay area blues: the effect of the housing crisis” – by Hadley Wickham, Deborah F. Swayne and David Poole – A chapter from the book, Beautiful Data: The Stories Behind Elegant Data Solutions, which serves as an excellent narrative on how to work with data in the real-world. The actual R code is at https://github.com/hadley/sfhousing [buy it]
Cookbook for R – by Winston Chang – “The goal of the cookbook is to provide solutions to common tasks and problems in analyzing data.” [buy it]
Beautiful plotting in R: A ggplot2 cheatsheet – by ZevRoss – One of the most thorough and helpful cheatsheets I’ve ever seen; this one is focused on making visualizations with ggplot2.
Sharon Machlis’s ggplot2 cheat sheet with interactive search-by-task – by Sharon Machlis – “Here’s your easy-to-use guide to dozens of useful ggplot2 R data visualization commands in a handy, searchable table. Plus, download code snippets to save yourself a boatload of typing.”
An Introduction to R – by The R-Core group – “This introduction to R is derived from an original set of notes describing the S and S-PLUS environments written in 1990–2 by Bill Venables and David M. Smith when at the University of Adelaide. We have made a number of small changes to reflect differences between the R and S programs, and expanded some of the material.”
An Introduction on How to Make Beautiful Charts With R and ggplot2 – by Max Woolf – Max Woolf’s short and readable intro to working with ggplot2.
Impatient R – by Burns Statistics – This is a tutorial (previously known as “Some hints for the R beginner”) for beginning to learn the R programming language. It is a tree of pages — move through the pages in whatever way best suits your style of learning.
A Layered Grammar of Graphics – by Hadley Wickham – R has been one of my least favorite languages to learn but being exposed to Wilkinson’s Grammar of Graphics via Hadley Wickham’s sublime implementation in ggplot2 has been worth the price of admission. This paper acts as an abbreviated form of Wickham’s 2009 manual on ggplot2. [buy it]
Tidy Data – by Hadley Wickham – Less about R and more about Hadley Wickham’s assertions about the ideal shape of data and how that informs the many R-lang libraries he’s created. A great read for both data novices and experts, as data cleaning/munging ends up being one of the hardest data science problems.
Advanced R – by Hadley Wickham – “The book is designed primarily for R users who want to improve their programming skills and understanding of the language. It should also be useful for programmers coming to R from other languages, as it explains some of R’s quirks and shows how some parts that seem horrible do have a positive side.” [buy it]
R Packages – by Hadley Wickham – “Packages are the fundamental units of reproducible R code. They include reusable R functions, the documentation that describes how to use them, and sample data. In this section you’ll learn how to turn your code into packages that others can easily download and use. Writing a package can seem overwhelming at first. So start with the basics and improve it over time. It doesn’t matter if your first version isn’t perfect as long as the next version is better.” [buy it]
Using R for Data Analysis and Graphics – by J H Maindonald – This PDF accompanies the book, “Data Analysis and Graphics Using R”:
“These notes are designed to allow individuals who have a basic grounding in statistical methodology to work through examples that demonstrate the use of R for a range of types of data manipulation, graphical presentation and statistical analysis. “ [buy it]
An Introduction to Statistical Learning with Applications in R – by Gareth James, Daniela Witten, Trevor Hastie and Robert Tibshirani – “This book provides an introduction to statistical learning methods. It is aimed for upper level undergraduate students, masters students and Ph.D. students in the non-mathematical sciences. The book also contains a number of R labs with detailed explanations on how to implement the various methods in real life settings, and should be a valuable resource for a practicing data scientist.” [buy it]
The Elements of Statistical Learning: Data Mining, Inference, and Prediction. – by Trevor Hastie, Robert Tibshirani, and Jerome Friedman – A more advanced treatment of the topics covered in “An Introduction to Statistical Learning with Applications in R” [buy it]
The R Inferno – by Burns Statistics – If you are using R and you think you’re in hell, this is a map for you. A book about trouble spots, oddities, traps, glitches in R.
ggplot2 book – by Hadley Wickham – This is the Github repo for Hadley Wickham’s upcoming revision to his still-superb manual for his ubiquitious ggplot2 visualization library.
Jenny Bryan’s Teaching materials for the R package ggplot2 – by Jenny Bryan – Slides, documents, and code used in UBC stats professor Jenny Bryan’s R-data-workshops.
What Netflix and AOL have in common
AOL and its unprofitable media ventures famously persisted because of revenues from AOL’s ostensibly obsolete dial-up service. Turns out Netflix is in a similar situation, in that its popular streaming service has yet to break even while its original business of sending out DVDs is bringing in hundreds of millions in profit. Via the New York Times’s Emily Steel:
Netflix now counts more than 65 million streaming members in more than 50 countries and plans to expand across the world in the next 18 months. But that breakneck growth comes at a cost: The company expects its streaming business to just break even globally through 2016 as it pours billions of dollars into content and an aggressive expansion.
Helping fuel that expansion is the company’s dwindling, often ignored DVD-by-mail operation, known for envelopes that wind up under sofa cushions and viewed by many as an anachronism in an era of lightning-fast streaming.
Netflix has 5.3 million DVD subscribers, a significant falloff from its peak of about 20 million in 2010; still, the division continues to churn out hundreds of millions of dollars in profit each year. And behind the scenes, engineers are trying to improve customer service and streamline the labor-intensive process of returning, sorting and shipping millions of DVDs each week.
The difference is that Netflix – unlike AOL, whose dial-up subscriber base dropped from 5.8 million to 2.6 from 2009 to 2013 – does not expect its DVD business to end:
Netflix has not put a life expectancy on its DVD division. Even as its subscriber count shrinks, the group has kept a core base of customers, particularly in rural zones with lackluster Internet service and among people who want access to the breadth of its selection, and executives expect it to stay around.
The other significant difference is that Netflix, according to the NYT, is devoting real resources and engineering to its legacy cash cow. The subscriber base may be dwindling, but advances in efficiency can make up for it:
To hold on to those customers — and the profits they bring — Netflix continues to deploy state-of-the-art technologies that help trim costs as well as improve customer service…
Here at the Fremont hub, Netflix used to employ about 100 people to handle the returning, sorting and shipping of the DVDs. Today, about 25 employees work through the night, largely assisting the machines. Their shifts start at about 2 a.m. By 8 a.m., the discs are out the door and the steady buzz of the machines starts to fade.
Onwards RAGBRAI 2015
The lapse in posting is because I’m on RAGBRAI 2015. And because I am severely dehydrated and sore.
Free Python Books and Resources; a short-list
Here’s a few of the more well-developed and freely-available Python-focused books, guides, and courses. Like most things on this new Jekyll blog of mine, it’s a work in progress. You can see the YAML-formatted list in the repo .
Automate the Boring Stuff with Python – by Al Sweigart – “Automate the Boring Stuff with Python is written for office workers, students, administrators, and anyone who uses a computer how to write small, practical programs to automate tasks on their computer.” [buy it]
Problem Solving with Algorithms and Data Structures using Python –
Donne Martin’s Interactive Coding Challenges – Continually updated, interactive, test-driven Python coding interview challenges (algorithms and data structures).
Python Cookbook – by David Beazley and Brian K. Jones – “If you need help writing programs in Python 3, or want to update older Python 2 code, this book is just the ticket. Packed with practical recipes written and tested with Python 3.3, this unique cookbook is for experienced Python programmers who want to focus on modern tools and idioms.” [buy it]
Software Carpentry’s Programming with Python – “The best way to learn how to program is to do something useful, so this introduction to Python is built around a common scientific task: data analysis. Our real goal isn’t to teach you Python, but to teach you the basic concepts that all programming depends on.”
From Python to Numpy – by Nicolas P. Rougier – An open-access book on numpy vectorization techniques.
Composing Programs – by John DeNero of UC Berkeley – “In the tradition of SICP, this text focuses on methods for abstraction, programming paradigms, and techniques for managing the complexity of large programs. These concepts are illustrated primarily using the Python 3 programming language.”
Dive Into Python: Python from novice to pro – by Mark Pilgrim – A free, book originally published in 2004, aimed at experienced programmers.
Codecademy’s Python Track – An interactive course in Python 2.
Learn Python the Hard Way (4th Ed.) – by Zed Shaw – “This book instructs you in Python by slowly building and establishing skills through techniques like practice and memorization, then applying them to increasingly difficult problems. Note that the Python 3 version is still in draft status.” [buy it]
The Hitchhiker’s Guide to Python – by Kenneth Reitz – This opinionated guide exists to provide both novice and expert Python developers a best-practice handbook to the installation, configuration, and usage of Python on a daily basis.
Introduction to Statistics 6.4 documentation – by Thomas Haslwanter – “I believe that I cover at least 90% of the problems that most physicists, biologists, and medical doctors encounter in their work.”
Think Python – The goal of this book is to teach you to think like a computer scientist. This way of thinking combines some of the best features of mathematics, engineering, and natural science. [buy it]
Probabilistic Programming & Bayesian Methods for Hackers – by Cam Davidson-Pilon – An intro to Bayesian methods and probabilistic programming from a computation/understanding-first, mathematics-second point of view.
The Little Book of Python Anti-Patterns – by QuantifiedCode – Welcome, fellow Pythoneer! This is a small book of Python anti-patterns and worst practices.
Test-Driven Development with Python – This book is my attempt to share with the world the journey I’ve taken from “hacking” to “software engineering”. It’s mainly about testing, but there’s a lot more to it, as you’ll soon see. [buy it]
Invent Your Own Computer Games with Python – by Al Sweigart – Invent with Python is for young adults, adult adults, and anyone who has never programmed before. [buy it]
Natural Language Processing with Python - Analyzing Text with the Natural Language Toolkit – by Steven Bird, Ewan Klein, and Edward Loper – This book serves both as a user manual for the great NLTK Python library and a primer on natural language processing.
OpenCV-Python Tutorials – by Alexander Mordvintsev & Abid K. – A set of tutorials covering the use of image processing and computer vision via the Python OpenCV library.
Making Games with Python & Pygame – by Al Sweigart – Making Games with Python & Pygame covers the Pygame library with the source code for 11 games. Making Games was written as a sequel for the same age range as Invent with Python. [buy it]
Hacking Secret Ciphers with Python – by Al Sweigart – Hacking Secret Ciphers with Python teaches complete beginners how to program in the Python programming language. The book features the source code to several ciphers and hacking programs for these ciphers. [buy it]
Intermediate Python — Python Tips 0.1 documentation – by Muhammad Yasoob Ullah Khalid – “The topics which are discussed in this book open up your mind towards some nice corners of Python language. This book is an outcome of my desire to have something like it when I was beginning to learn Python.”
Python for Scientists and Engineers – by Shantnu Tiwari –
Other lists and resources
- vhf/free-programming-books#python
- r/learnpython - the size of this subreddit is a decent metric of how popular Python has become.
- Al Sweigart has a list of non-free books he recommends - “These books take a more conventional approach to covering programming concepts. They don’t focus on having complete source code for small projects or games, but they do explain programming concepts fairly well.”
Non-free
The list of great books for purchase is too long a list, but of the things I’ve recently purchased and read, Fluent Python is just stellar. I’m still a relative novice at Python, but this book (which focuses on 3.x) was both immediately accessible and revelatory. I’d compare it favorably to Metaprogramming Ruby – both books eloquently expose the power of their languages for relatively experienced programmers.
Interested in the R language? I’m also putting together a shortlist of free R resources.
My favorite iPhone app: Ambiance
On HN this morning, I saw this neat Hipster Sound website which lets you enjoy the bustling noise of a coffee shop from the comfort of your home. However, I was reminded of how much I appreciate the 99-cent Ambiance app on iOS, which lets you download thousands of background ambient noises and mix them into tracks. Combined with the phone’s timer, Ambiance is responsible for me getting a lot of work done throughout the day.
Some caveats: Apparently there’s a Mac Desktop version. However, it sells for $9.99 and hasn’t been updated since 2012, so I don’t think it’s a good buy. When I had an Android phone I bought Ambiance for it, but the Android version was noticeably inferior in that the sound would skip at regular intervals. It’s such an annoying bug that you should just not buy it for Android.
Other alternatives as mentioned in the HN thread:
- A Soft Murmur - “he has worked very hard on blending the loops. They are not detectable in the 100 hours or so I have listened to them.”
- Defonic
- Noisli
- Simply Noise
- Rainy mood
- Pluvior - more rainy sounds, like “Manhattan at night”
- Concentr.me
How to download the history of your physical Amazon orders
After seeing this post on r/ruby about importing your Amazon order history into SQLite, I thought: I kind of want to know how much I’ve spent on Amazon…but not enough to write a program tonight. While I didn’t find an API for order history, Amazon has a convenient order history report-building tool (login required) that can generate a CSV of every Amazon item you’ve shipped in the past 10 years.
Here’s what the order form looks like:
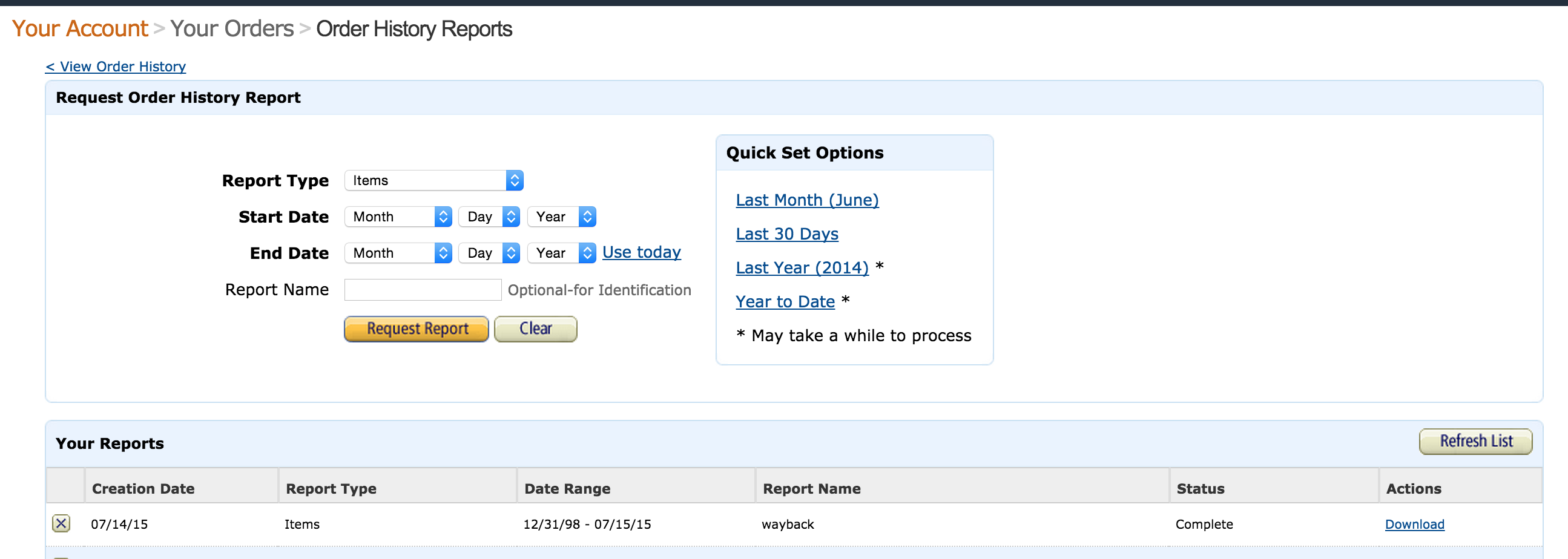
The form lets you select a date at the beginning of 2006, but the earliest order in my history was in late July 2006, i.e. 10 years ago from today. I used the web inspector to tamper with the form’s POST request but still didn’t receive any data before July 2006 (according to my old GMails, I’ve ordered at least one Simpsons DVD set pre-2006).
Another limitation of this data: again, the Order History Form only includes physically shipped items. So it doesn’t include digital purchases, such as streaming movies and Kindle books.
According to the report I downloaded, since 2006, I’ve ordered roughly 300 different physical items from Amazon. Some items were purchased in quantities greater than 1, but Amazon records a row for every item per order. For example, my dataset includes several entries for this Macbook keyboard cover.
I’m pretty surprised at how low that total number of different items is. I would’ve guessed that I’ve made at least 300 separate orders – each order containing multiple kinds of items – but I’ve actually made 160 orders. I’ve been a long-time Amazon Prime customer partly because I had thought I ordered from Amazon so often, but the data seems to tell a different story.
(note: I order Kindle books frequently, so that’s probably why I think I’ve ordered much more than what my physical order history shows)
- The earliest thing in my order report is a $13.90 copy of Jagged Alliance 2. No surprise there, that game is the best.
- Most expensive thing I’ve paid for is this $599.00 camera adapter to attach Canon lenses to my Sony cameras.
- I stopped buying DVDs for myself after 2007, which is when I joined Netflix. Though I did purchase the complete set for The Wire in 2011 and a copy of Idiocracy in 2009, as neither were then available for streaming.
Using a pivot table, this is the top 3 categories by number of items and price paid:
| Category | Count | Price |
|---|---|---|
| Personal Computers | 55 | $4,777.44 |
| Electronics | 52 | $3,565.31 |
| Office Product | 18 | $788.88 |
Ouch. Though not surprising…the “Personal Computers” category also consists of hard drives and memory cards, and “Electronics” includes digital cameras and accessories. So that seems about right for 10 years of memory capacity, laptops, monitors, and camera equipment, not including what I’ve spent at the Apple Store.
If you’re curious about the kind of data the report contains, here are the headers and the values for a sample order. The ASIN/ISBN field contains the unique ID that you can append to http://www.amazon.com/gp/product/ in order to get the product page URL:
| Header | Sample value |
|---|---|
| Order Date | 10/05/09 |
| Order ID | 555-8675309-8675309 |
| Title | Idiocracy |
| Category | DVD |
| ASIN/ISBN | B000K7VHOG |
| Website | Amazon.com |
| Release Date | 01/08/07 |
| Condition | new |
| Seller | Amazon.com |
| Seller Credentials | |
| List Price Per Unit | 14.98 |
| Purchase Price Per Unit | 8.99 |
| Quantity | 1 |
| Payment - Last 4 Digits | 9999 |
| Purchase Order Number | |
| Ordering Customer Email | dan@email.com |
| Shipment Date | 10/09/09 |
| Shipping Address Name | Dan Haus |
| Shipping Address Street 1 | 100 Broadway |
| Shipping Address Street 2 | |
| Shipping Address City | NEW YORK |
| Shipping Address State | NY |
| Shipping Address Zip | 10006-3734 |
| Order Status | Shipped |
| Carrier Name & Tracking Number | |
| Item Subtotal | 8.99 |
| Item Subtotal Tax | 0.80 |
| Tax Exemption Applied | |
| Tax Exemption Type | |
| Exemption Opt-Out | |
| Buyer Name | DAN HAUS |
| Currency | USD |
| External Item Number |
Here’s the Create an Order History Report page: https://www.amazon.com/gp/b2b/reports
Here’s a help page about how to use that page.
Here’s chrisb’s Github repo for importing your Amazon order history into SQLite/ActiveRecord.
Moving beyond copy-and-paste when learning to program
One of the key hacks to efficiently learning how to code is to copy others’ code.
But this does not mean copying-and-pasting. It means typing each line, character, and indentation yourself. On the surface, this seems tedious. But if you don’t know how to program, you have to start somewhere. Even as competent programmer, I often start the day by doing verbatim copying of someone’s code. It’s a leisurely activity when the coffee hasn’t quite kicked in yet, and I almost always notice something about the code that I didn’t while just reading it.
However, I admit to having the bad habit of copying-and-pasting my own code, because I’ve told myself “Well, I’ve already written it once before…just because I can’t remember it off hand doesn’t mean I need to re-type it.” So I’m trying to get better at kicking that habit.
Here are a few ways to practice copying code while getting better at your operating system:
Open adjacent windows
This is pretty straightforward. Open two windows, code-to-copy on one side, new file on the other, and then type away. It may seem brainless but it is still better than copy-pasting.
TK: Post an animated GIF
One window at a time
I prefer opening the code-to-copy in one full window, and the new file in another window, and having the two windows lie on top of each other so that I can only see one at a time. In the new file, I type as much as I can remember. And when I need to, I hit Cmd + ~ to quickly flip to and glance at the code-to-copy, and the Cmd + ~ again to type what I’ve just seen. That extra step seems to make my brain work harder at focusing on the details.
Hey
TK: Post an animated GIF
via the Intro to Zed Shaw’s Learn Python the Hard Way (emphasis added):
The one skill that separates bad programmers from good programmers is attention to detail. In fact, it’s what separates the good from the bad in any profession. You must pay attention to the tiniest details of your work or you will miss important elements of what you create. In programming, this is how you end up with bugs and difficult-to-use systems
By going through this book, and copying each example exactly, you will be training your brain to focus on the details of what you are doing, as you are doing it…
You must type each of these exercises in, manually. If you copy and paste, you might as well not even do them. The point of these exercises is to train your hands, your brain, and your mind in how to read, write, and see code. If you copy-paste, you are cheating yourself out of the effectiveness of the lessons.
A (proposed) guide for exploring the Open FEC API
More fine work by 18F and the USDS.
The new API is just very tasty icing on the cake. The FEC has long been in the forefront of transparency in the U.S. federal government. As the Sunlight post says:
The FEC is a model disclosure authority: It has made federal campaign finance data available through a searchable web portal, in bulk CSV files, and, most impressively, a live feed of submitted disclosures. On Influence Explorer, we’ve made use of each of these sources in different ways — most recently turning that live feed into a searchable data resource, our Real-Time Federal Campaign Finance tracker.
For my data journalism classes, I’ve been remiss in not covering campaign finance. The data is intimidating. But now, with the Sunlight’s model example of how to write a how-to, I think the OpenFEC API can be a great entry point into learning about APIs, JSON, data, and American politics.
Some topics I’d like to cover:
- How to find campaign contribution totals per cycle
- Given a candidate, how to find totals per cycle. Or lifetime of committee.
subscribe via RSS